聪明人要下死功夫
Apache Kafka
- 开源的消息引擎系统
Messaging System- 消息引擎系统是一组规范。企业利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递
参考维基百科 - 通俗版:系统 A 发送消息给消息引擎系统,系统 B 从消息引擎系统中读取 A 发送的消息
- 消息引擎系统是一组规范。企业利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递
- 消息引擎基本要求
- 消息引擎传输的对象是消息;
- 如何传输消息属于消息引擎设计机制的一部分。
- 消息编码格式
- 纯二进制的字节序列
- 传输协议
- 点对点模型
- 发布/订阅模型
- 作用
- 削峰填谷:对抗上下游系统 TPS 的错配以及瞬时峰值流量
- 发送方和接收方的松耦合
Kafka术语
消息:Record
- Kafka 处理的主要对象
主题:Topic
- 发布订阅的对象;承载消息的逻辑容器
分区:Partition
- 一个有序不变的消息序列。每个主题下可以有多个分区。
- 等同于 Sharding Region
- Kafka 中的分区机制指的是将每个主题划分成多个分区(Partition),每个分区是一组有序的消息日志。
- 生产者生产的每条消息只会被发送到一个分区中,也就是说如果向一个双分区的主题发送一条消息,这条消息要么在分区 0 中,要么在分区 1 中。
- Kafka 的分区编号是从 0 开始的
- 每个分区下可以配置若干个副本,其中只能有 1 个领导者副本和 N-1 个追随者副本
一个topic 可以拥有若干个partition(从 0 开始标识partition ),分布在不同的broker 上, 实现发布与订阅时负载均衡。producer 通过自定义的规则将消息发送到对应topic 下某个partition,以offset标识一条消息在一个partition的唯一性。
副本:Replica
- Kafka 中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。
- replica 包含两种类型:leader 副本、follower副本,
- 领导者副本 Leader Replica:对外提供服务
- 追随者副本 Follow Replica:被动的追随领导者副本,不会对外提供服务
一个partition拥有多个replica,提高容灾能力。
生产者:Producer
- 向主题发布消息的客户端应用程序
消费者:Consumer
- 订阅主题消息的客户端应用程序
消息位移:Offset
- 分区中每条消息的位置信息,是一个单调递增且不变的值
- 生产者向分区写入消息,每条消息在分区中的位置信息由一个叫位移(Offset)的数据来表征
- 分区位移总是从 0 开始
消费者位移:Consumer Offset
表征消费者消费进度,每个消费者都有自己的消费者位移。
查看消费者位移,以及查看未消费消息数
1
2
3
4
5
6
7
8
9> ./kafka-consumer-groups.sh --bootstrap-server 192.168.87.102:9092 --group testgroup --describe
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG
test1 0 0 0 0
test1 2 1 2 1
test1 1 1 1 0
# CURRENT-OFFSET表示当前分区消费到的Offset
# LOG-END-OFFSET表示当前分区的最大Offset
# LAG表示未消费的数量
消费者组:Consumer Group
- 多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
消费topic 的消息, 一个topic 可以让若干个consumer消费,若干个consumer组成一个 consumer group ,一条消息只能被consumer group 中一个consumer消费,若干个partition 被若干个consumer 同时消费,达到消费者高吞吐量
- 多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
重平衡:Rebalance
- 消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。
- Rebalance 是 Kafka 消费者端实现高可用的重要手段
客户端:Clients
- 生产者+消费者
服务端:Broker
- 一个Kafka集群由多个Broker组成
- 服务代理节点,Kafka服务实例。
- Broker负责接收和处理客户端发送过来的请求,以及对消息进行持久化
- Broker一般是分布式部署,实现高可用
备份机制:Replication
副本工作机制
- 生产者总是向领导者副本写消息;而消费者总是从领导者副本读消息。
- 追随者副本,它只做一件事:向领导者副本发送请求,请求领导者把最新生产的消息发给它,这样它能保持与领导者的同步。
- 副本是在分区层级下的,即每个分区可配置多个副本实现高可用
- leader副本负责读写请求,follower 副本负责同步leader副本消息,通过副本选举实现故障转移。
Kafka追随者副本不对外提供服务的意义
- 如果允许follower副本对外提供读服务(主写从读),首先会存在数据一致性的问题,消息从主节点同步到从节点需要时间,可能造成主从节点的数据不一致。
- 主写从读无非就是为了减轻leader节点的压力,将读请求的负载均衡到follower节点,如果Kafka的分区相对均匀地分散到各个broker上,同样可以达到负载均衡的效果,没必要刻意实现主写从读增加代码实现的复杂程度
伸缩性 Scalability
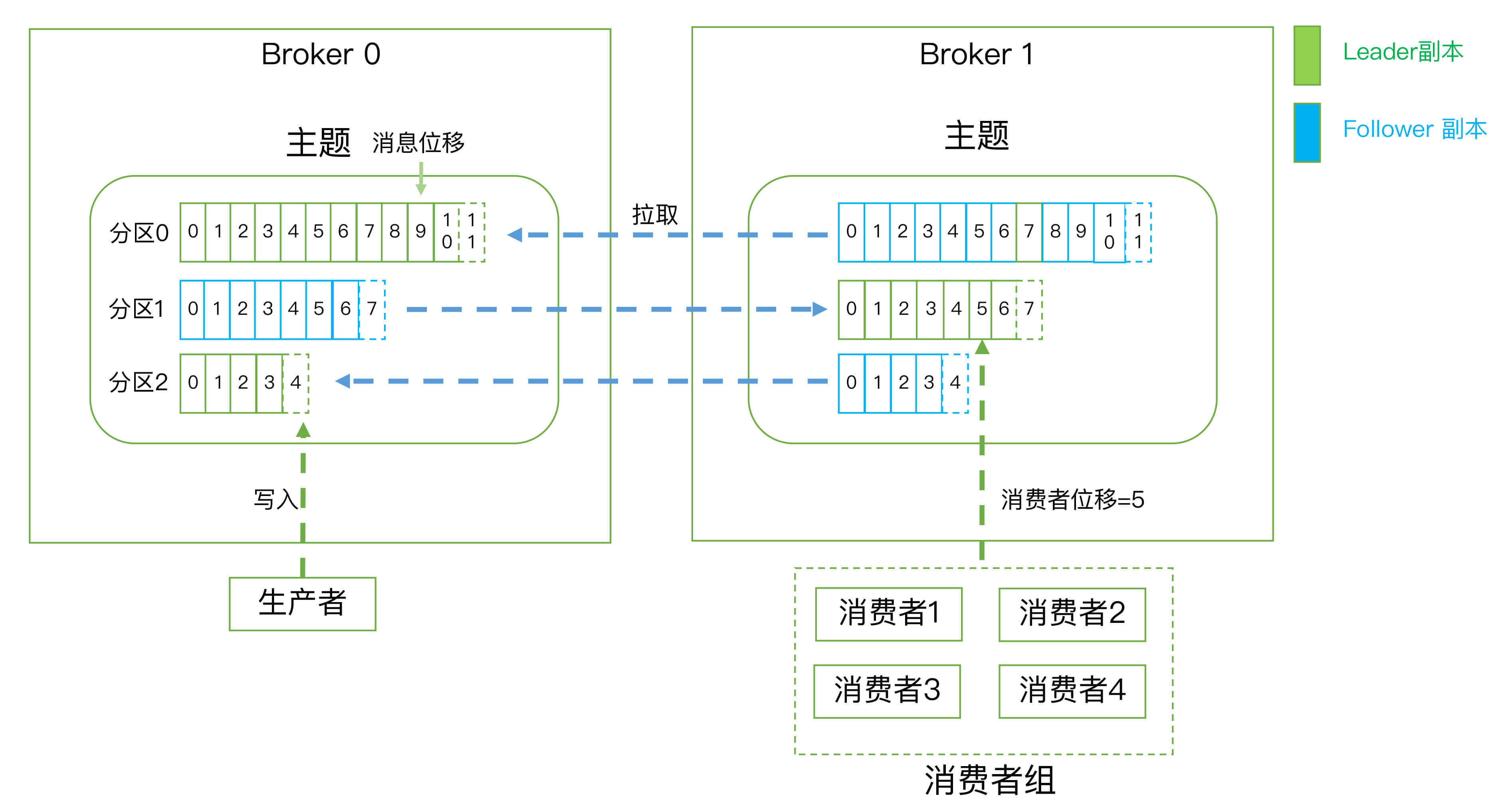
三层消息架构
主题层:每个主题可以配置 M 个分区(保证伸缩性),而每个分区又可以配置 N 个副本。
分区层:(副本概念是在分区层定义的)每个分区的 N 个副本中只能有一个充当领导者角色,对外提供服务;其他 N-1 个副本是追随者副本,只是提供数据冗余之用。
消息层:分区中包含若干条消息,每条消息的位移从 0 开始,依次递增
客户端程序只能与分区的领导者副本进行交互(追随者副本只是冗余保存数据,保证数据不会丢失)
Kafka体系架构=M个producer +N个broker +K个consumer+ZK集群
Kafka Broker如何持久化数据
- Kafka 使用消息日志(Log)来保存数据
- 一个日志就是磁盘上一个只能追加写(Append-only)消息的物理文件。
- 因为只能追加写入,故避免了缓慢的随机 I/O 操作,改为性能较好的顺序 I/O 写操作,这也是实现 Kafka 高吞吐量特性的一个重要手段
- Kafka 必然要定期地删除消息以回收磁盘
- 通过日志段(Log Segment)机制。在 Kafka 底层,一个日志又进一步细分成多个日志段,消息被追加写到当前最新的日志段中,当写满了一个日志段后,Kafka 会自动切分出一个新的日志段,并将老的日志段封存起来
- Kafka 在后台还有定时任务会定期地检查老的日志段是否能够被删除,从而实现回收磁盘空间的目的
partition在机器磁盘上以log 体现,采用顺序追加日志的方式添加新消息、实现高吞吐量
消费者组
- 消费者组(Consumer Group)
- 所谓的消费者组,指的是多个消费者实例共同组成一个组来消费一组主题。这组主题中的每个分区都只会被组内的一个消费者实例消费,其他消费者实例不能消费它。
- 为什么要引入消费者组呢?主要是为了提升消费者端的吞吐量。多个消费者实例同时消费,加速整个消费端的吞吐量(TPS)。
重平衡
消费者组里面的所有消费者实例不仅“瓜分”订阅主题的数据,而且更酷的是它们还能彼此协助。假设组内某个实例挂掉了,Kafka 能够自动检测到,然后把这个 Failed 实例之前负责的分区转移给其他活着的消费者。这个过程就是 Kafka 中大名鼎鼎的“重平衡”(Rebalance)。
和elastic-job的sharding分片类似?将一个任务分给多个实例运行,一个实例只执行其中部分,通过一个field来标志每个实例负责的部分任务,如果某一个实例失败,将这个失败的任务分给其他执行完了的实例。不过这种方式是通过zookeeper的中心化的服务来实现的。
消费者位移
- 消费者位移(Consumer Offset)
- 消费者位移与分区位移的区别
- 消费者位移:可能是随时变化的,它是消费者消费进度的指示器,每个消费者有着自己的消费者位移。
- 分区位移:表征的是分区内的消息位置,它是不变的,即一旦消息被成功写入到一个分区上,它的位移值就是固定的了。
Kafka不只是消息引擎
Apache Kafka 是消息引擎系统,也是分布式流处理平台(Distributed Streaming Platform)
名字由来:取自Franz Kafka 文学作家
2011 年 Kafka 正式进入到 Apache 基金会孵化并于次年 10 月顺利毕业成为 Apache 顶级项目
Kafka 社区于 0.10.0.0 版本正式推出了流处理组件 Kafka Streams,也正是从这个版本开始,Kafka 正式“变身”为分布式的流处理平台,而不仅仅是消息引擎系统了
Apache Kafka 是和 Apache Storm、Apache Spark 和 Apache Flink 同等级的实时流处理平台
设计之初的三个特性
- 提供一套 API 实现生产者和消费者;
- 降低网络传输和磁盘存储开销;
- 实现高伸缩性架构。
Kafka流处理优势
- 更容易实现端到端的正确性(Correctness)
- 自己对于流式计算的定位:Kafka Streams 是一个用于搭建实时流处理的客户端库而非是一个完整的功能系统
Kafka还可以作为分布式存储系统,实际用的较少
流处理要最终替代它的“兄弟”批处理需要具备两点核心优势:
要实现正确性和提供能够推导时间的工具。
实现正确性是流处理能够匹敌批处理的基石
正确性的基石则是要求框架能提供精确一次处理语义,即处理一条消息有且只有一次机会能够影响系统状态目前主流的大数据流处理框架都宣称实现了精确一次处理语义,但这是有限定条件的,即它们只能实现框架内的精确一次处理语义,无法实现端到端的。这是为什么呢?
姑且把 Spark 简单理解为一个生产者。生产者向 Broker 发送消息,消息被 Broker 成功接收并完成了持久化,但因为网络问题导致生产者认为消息的发送是失败的,生产者会进行重试。这显示就违背了精确一次的处理语义。
应该选择哪种Kafka?
Kafka Connect 通过一个个具体的连接器(Connector),串联起上下游的外部系统。
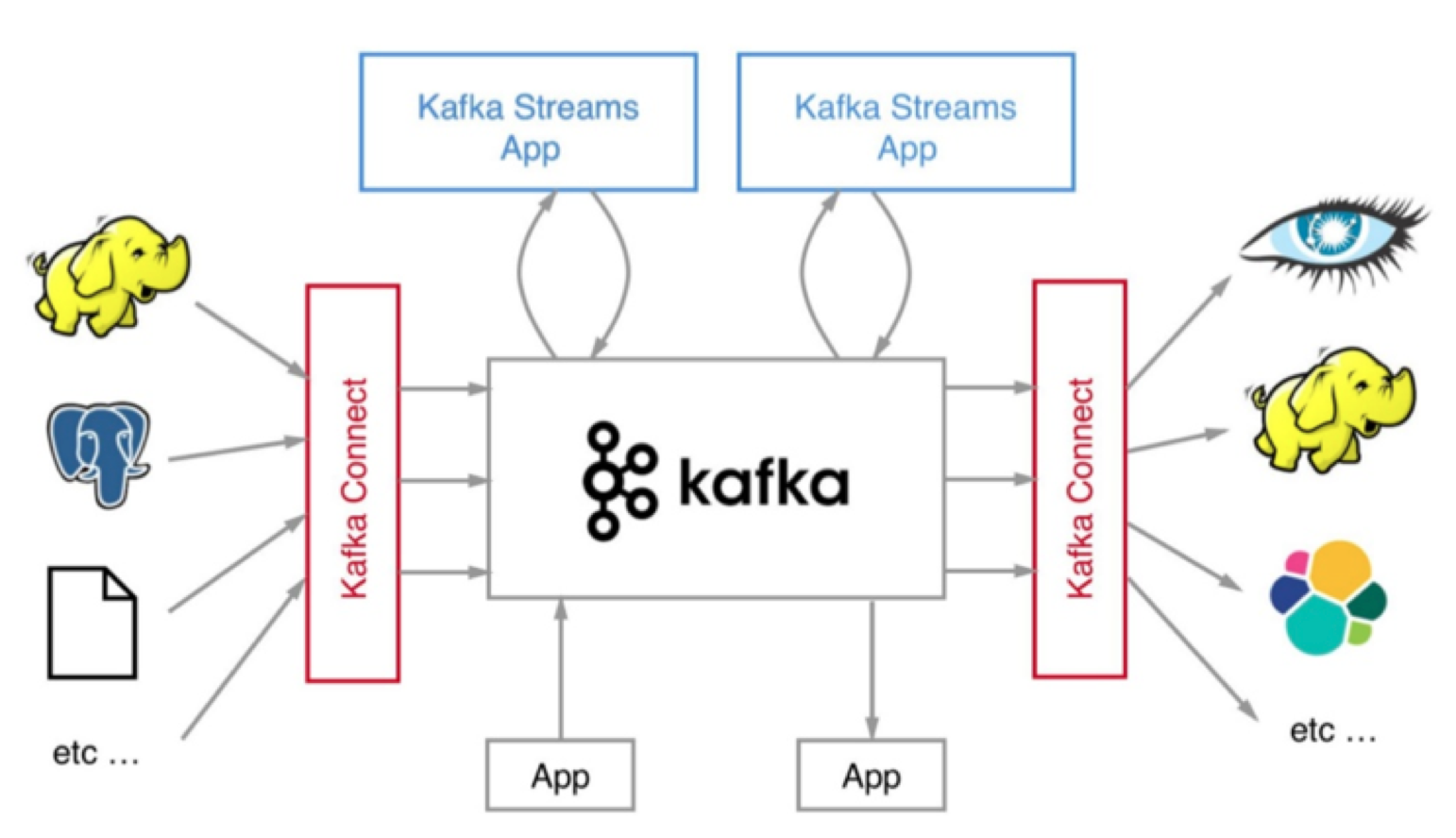
几种 Kafka?
- Apache Kafka:社区版 Kafka
- Confluent Kafka:从事商业化 Kafka 工具开发,比如跨数据中心备份、Schema 注册中心以及集群监控工具等
- Cloudera/Hortonworks Kafka:Cloudera 提供的 CDH 和 Hortonworks 提供的 HDP 是非常著名的大数据平台;CDH Kafka 和 HDP Kafka
Kafka 的 3 个创始人 Jay Kreps、Naha Narkhede 和饶军创始人创办Confluent 公司
Apache Kafka
- 优势在于迭代速度快,社区响应度高,使用它可以让你有更高的把控度;
- 缺陷在于仅提供基础核心组件,缺失一些高级的特性;没有提供任何监控框架或工具
- Apach kafka原生不提供监控,但有一些开源的监控框架;比如 Kafka manager
Confluent Kafka
- 分为免费版和企业版两种
- 免费版还包含 Schema 注册中心和 REST proxy 两大功能、更多的连接器
- 企业版提供的功能最有用的当属跨数据中心备份和集群监控两大功能了
- 如果你需要用到 Kafka 的一些高级特性,那么推荐你使用 Confluent Kafka。
- 优势在于集成了很多高级特性且由 Kafka 原班人马打造,质量上有保证;
- 缺陷在于相关文档资料不全,普及率较低,没有太多可供参考的范例。
多个数据中心之间数据的同步以及对集群的监控历来是 Kafka 的痛点
CDH/HDP Kafka
- 如果你需要快速地搭建消息引擎系统,或者你需要搭建的是多框架构成的数据平台且 Kafka 只是其中一个组件,那么我推荐你使用这些大数据云公司提供的 Kafka。
- 优势在于操作简单,节省运维成本;
- 缺陷在于把控度低,演进速度较慢。
Kafka版本号

前面的版本号是编译 Kafka 源代码的 Scala 编译器版本。
Kafka 服务器端的代码完全由 Scala 语言编写;Scala 是 JVM 系的语言
对于 kafka-2.11-2.1.1 的提法,真正的 Kafka 版本号实际上是 2.1.1
- 2.1.1 又表示什么呢?前面的 2 表示大版本号,即 Major Version;中间的 1 表示小版本号或次版本号,即 Minor Version;最后的 1 表示修订版本号,也就是 Patch 号。
- Kafka 社区在发布 1.0.0 版本后特意写过一篇文章,宣布 Kafka 版本命名规则正式从 4 位演进到 3 位,比如 0.11.0.0 版本就是 4 位版本号。
- 大版本号 - 小版本号 - Patch 号
Kafka 目前总共演进了 7 个大版本,分别是 0.7、0.8、0.9、0.10、0.11、1.0 和 2.0
0.7 版本:只提供了最基础的消息队列功能,甚至连副本机制都没有
0.8 版本:引入了副本机制,至此Kafka 成为了一个真正意义上完备的分布式高可靠消息队列解决方案。生产和消费消息使用的还是老版本的客户端 API,所谓的老版本是指当你用它们的 API 开发生产者和消费者应用时,你需要指定 ZooKeeper 的地址而非 Broker 的地址。 0.8.2.0 版本社区引入了新版本 Producer API,即需要指定 Broker 地址的 Producer
0.9.0.0 版本:增加了基础的安全认证 / 权限功能,使用 Java 重写了新版本消费者 API,引入 Kafka Connect 组件用于实现高性能的数据抽取。新版本 Producer API 在这个版本中算比较稳定了;千万别用 0.9 的新版本 Consumer API,因为 Bug 超多的,。
0.10.0.0版本:里程碑式的大版本,引入了 Kafka Streams,正式升级成分布式流处理平台。自 0.10.2.2 版本起,新版本 Consumer API 算是比较稳定了。
0.11.0.0 版本:引入了两个重量级的功能变更:一个是提供幂等性 Producer API 以及事务(Transaction) API;另一个是对 Kafka 消息格式做了重构。事务 API 主要是为 Kafka Streams 应用服务的。因为格式变更引起消息格式转换而导致的性能问题在生产环境中屡见不鲜,所以你一定要谨慎对待 0.11 版本的这个变化。这个版本中各个大功能组件都变得非常稳定了。
1.0 和 2.0 版本:主要还是 Kafka Streams 的各种改进,在消息引擎方面并未引入太多的重大功能特性。如果你是 Kafka Streams 的用户,至少选择 2.0.0 版本吧。
建议是尽量使用比较新的版本。如果你不能升级大版本,我也建议你至少要升级到 0.8.2.2 这个版本,因为该版本中老版本消费者 API 是比较稳定的。另外即使你升到了 0.8.2.2,也不要使用新版本 Producer API,此时它的 Bug 还非常多。
如果你依然在使用 0.10 大版本,我强烈建议你至少升级到 0.10.2.2 然后使用新版本 Consumer API。还有个事情不得不提,0.10.2.2 修复了一个可能导致 Producer 性能降低的 Bug。基于性能的缘故你也应该升级到 0.10.2.2。
不论你用的是哪个版本,都请尽量保持服务器端版本和客户端版本一致,否则你将损失很多 Kafka 为你提供的性能优化收益。
扫描二维码,分享此文章